Charset vs. encoding
I have always been discouraged by the fact that the words "charset" and "encoding" seem to be used interchangeably—if they are the same term, why use both words?
- The HTML specification uses both words interchangeably:
"The
charsetattribute specifies the character encoding used by the document." - The XML specification seems to do a similar thing, only it specifies a declaration named
encodinginstead ofcharset, but recommends the names of IANA charsets to be specified as values:"It is recommended that character encodings registered (as charsets) with the Internet Assigned Numbers Authority, other than those just listed, be referred to using their registered names"
.
My patience burst, and I decided to dive into the matter. This post is essentially a version of the Unicode Character Encoding Model shortened and creatively retold by me, and I invite you to read the original instead, if you are so inclined. I also recommend reading the article "The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)" by Joel Spolsky.
Contents
Abstract character repertoire (ACR)
Abstract character repertoire (ACR)—an unordered set of abstract characters. Abstract characters are often referred to as just characters.
The word "abstract" emphasizes that these objects are defined by convention.
For example, the capital letter "A" in the Latin alphabet is an abstract character named LATIN CAPITAL LETTER A in the Unicode standard.
Regardless of the glyph we use to represent this character, e.g.,
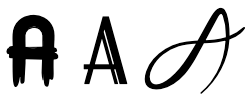 ,
we mean the same abstract character.
,
we mean the same abstract character.
Character map (CM)
Character map (CM), a.k.a. charset—a mapping from a sequence of members of an ACR to a sequence of bytes.
CM = coded character set (CCS) + character encoding form (CEF) + character encoding scheme (CES)
So a charset is not actually a set of characters, as one might have anticipated based on the word choice.
CES in the above definition may be compound, which means there may be multiple CEF/CCS for a given CM, which is also then called compound. This definition is to an extent similar to the definition given by the RFC 2978, though it does not seem like they are identical, and the definition in the RFC makes much less sense to me than the one in the Unicode standard.
Coded character set (CCS)
Coded character set (CCS), a.k.a. code page—a mapping from an ACR to the set of non-negative integers, which are called code points. If a CCS assigns a code point to an abstract character, then such a code point is called assigned character, while the associating itself is called an encoded character.
Not all code points are assigned to abstract characters, there are different types of code points. The code points we are interested in are called Unicode scalar values1.
Character encoding form (CEF)
Character encoding form (CEF)—a mapping from Unicode scalar values used in a CCS to the set of sequences of code units. While a code unit is an integer with a bit width fixed for a given CEF, the sequences of code units representing code points do not necessarily have the same length.
This concept arises from the way numbers are represented in computers—as sequences of bytes; thus a CES enables character representation as actual data in a computer. For example, the UTF-8 CEF is a variable-width encoding form that represents code points as a mix of one to four 8-bit code units in the Unicode standard.
Character encoding scheme (CES)
Character encoding scheme (CES)—a reversible transformation of sequences of code units to sequences of bytes.
Applying CES is the last step in the process of representing an abstract character as binary data in a computer. It may introduce compression or care about byte order. For example, UTF-16 CES cares about byte order and has the little endian (LE) / big endian (BE) byte order marks (BOM).
Examples
Coded character set
ISO/IEC 10646 defines, among other things, a CCS called Universal Coded Character Set (UCS). The Unicode standard uses this CCS. UCS includes many interesting characters, e.g., ⑧ 🦠 ∬, but not everything you might want, for example, it does not include Apple logo. The complete CCS used by the Unicode standard is available at https://www.unicode.org/charts/.
Unicode code points are written in the format U+HHHH or U+HHHHHH,
where H is a hexadecimal digit, and range from U+0000 (0) to U+10FFFF (1_114_111).
Character map
We often refer to something called "UTF-8" as "encoding",
but Java SE API specification refers to it as Charset.
So what is it exactly? According to ISO/IEC 10646, or the Unicode standard
(they are kept synchronized),
there is UTF-8 CEF and UTF-8 CES.
RFC 3629 defines UTF-8 charset that is registered as an IANA character set.
So we may say that
UTF-8 charset = UCS CCS + UTF-8 CEF + UTF-8 CES.
-
Values of the primitive type
charin Rust are Unicode scalar values, and are always 32 bit in size. Unfortunately, values of its counterpart in Java are 16-bit unsigned integers representing UTF-16 code units. This is because the Java language was unfortunate enough to appear when Unicode was still representing all abstract characters as 16-bit numbers, i.e., it was representing less characters than it does currently. Since then, the Java SEStringclass gained methods that can work with Unicode code points, but thecharstayed unchanged for the sake of backward compatibility.